Best Way to Handle Duplicate Rows in Power Query
Learn the best techniques to handle duplicate rows in Power Query and keep your data clean and reliable. This blog explores step-by-step methods to identify, remove, or manage duplicates while preserving data integrity. Master these skills to streamline your data preparation process and create accurate, actionable reports.
POWER BIPOWER QUERY
Clean Your Data Like a Pro: Handling Duplicate Rows in Power Query
When working with data, duplicates can sneak in and disrupt your analysis. Power Query, the data transformation tool in Power BI, offers powerful features to identify and handle duplicate rows efficiently. In this guide, we’ll explore the best ways to manage duplicates in Power Query.
What Are Duplicate Rows?
Duplicate rows occur when two or more rows in a dataset contain identical values in one or more columns. While duplicates can sometimes be intentional, they often need to be removed or consolidated for accurate analysis.
Why Remove Duplicate Rows?
· Ensure Data Accuracy: Duplicate rows can inflate metrics like totals and averages.
· Streamline Reports: Clean data ensures faster processing and clearer visualizations.
· Maintain Consistency: Eliminate redundant entries to maintain a single source of truth.
Step 1: Load Your Data into Power Query
1. Open Power BI Desktop and click Get Data.
2. Select your data source (e.g., Excel, CSV, or database) and click Transform Data to open Power Query Editor.
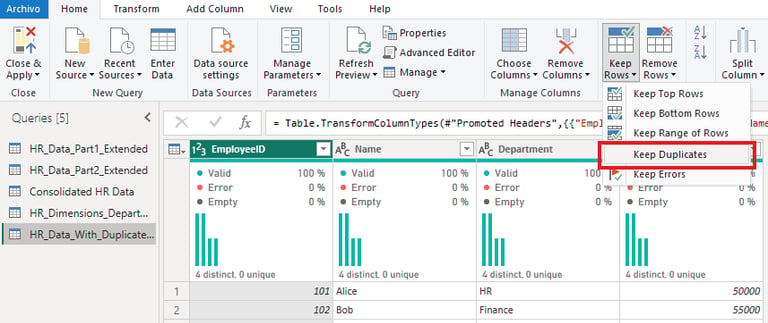
Step 2: Identify Duplicate Rows
Power Query allows you to identify duplicates based on selected columns:
1. Highlight the columns you want to check for duplicates. If you’re checking for duplicates across all columns, select them all.
2. Go to the Home tab and click Keep Rows > Keep Duplicates.
a. Power Query will display only the rows that are duplicated based on your selection.
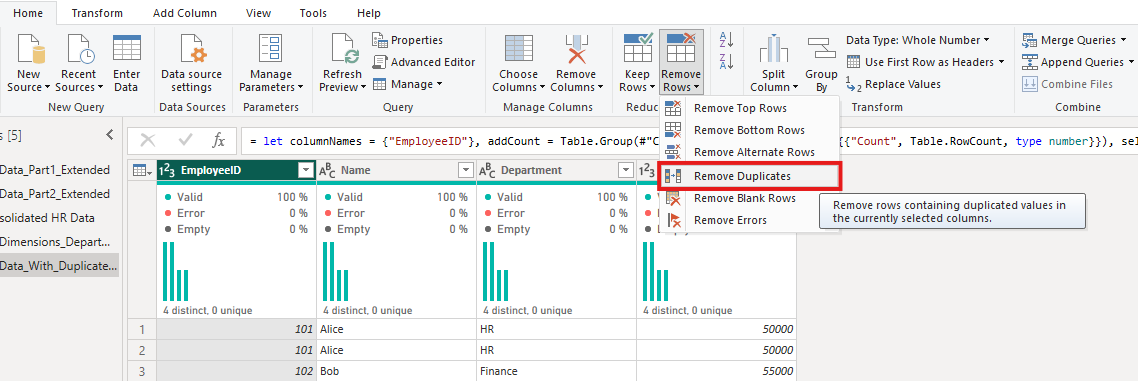
Step 3: Remove Duplicate Rows
To remove duplicate rows:
1. Select the relevant columns for checking duplicates.
2. Go to the Home tab and click Remove Rows > Remove Duplicates.
3. Power Query will keep only the first occurrence of each duplicate and remove the rest.
Step 4: Handle Duplicates Intelligently
Sometimes, you don’t want to simply remove duplicates but need to handle them intelligently. Here are some advanced techniques:
1. Aggregate Duplicates:
a. If duplicates represent grouped data (e.g., sales by customer), use Group By in Power Query.
b. Specify the column to group by and choose an aggregation method (e.g., sum, average).
2. Flag Duplicates:
a. Add an index column before removing duplicates. This allows you to track which rows were removed.
b. Use the Add Column tab and select Index Column.
3. Create a Distinct Table:
a. If you need a unique list of values, create a distinct table by removing duplicates and saving the results as a new query.
Best Practices for Handling Duplicates
1. Define Your Criteria: Clearly identify which columns to check for duplicates. For example, customer IDs may be unique, but names might repeat.
2. Keep a Backup: Before removing duplicates, save a copy of the original dataset.
3. Use Sorting: Sort your data logically before removing duplicates to prioritize which rows are retained.
4. Document Your Steps: Add meaningful names to your transformation steps to track your process in Power Query Editor.
Why Handling Duplicates Matters
Cleaning your data by handling duplicates ensures accurate reporting and trustworthy insights. Power Query simplifies this process, offering both quick fixes and advanced options for more nuanced cases.
Need help optimizing your Power BI workflows? Contact Insighthuis for expert guidance. Let’s ensure your data is clean, reliable, and ready to drive impactful decisions.
Start managing duplicates effectively today!
Insighthuis, building success with data-driven decisions.
Maastricht, Netherlands
Call us: +31 (6) 49158701 / +31 (6)85450973
Contact us: info@insighthuis.com